4 Decades of AI Compute
AI training requires more and more computation. But how much more? In this analysis I show that computation for training AI models has doubled roughly every 9 months during the last 40 years. Significance and implications discussed.
Article Breakdown
Why do we care about this trend?
Understanding AI progress is crucial for planning, strategy, and policymaking but quantifying it compactly is difficult. Interestingly, whether we like it or not, computation◥ has been an annoyingly reasonable proxy for AI progress. The reason is evident, yet also somewhat unpleasant: incorporating domain knowledge or rules into AI systems helps only in the short run but breakthrough progress has been achieved only by methods that scale with compute◥. Therefore, AI compute tells a lot about AI progress. Even though this might change in the future, I sure wouldn't bet my money on that. As succinctly explained in the famous Bitter Lesson⧉ by Professor Richard Sutton:
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. (...) Researchers seek to leverage their human knowledge of the domain, but the only thing that matters in the long run is the leveraging of computation.
And slightly more direct by possibly the greatest Speech Recognition scientist, Frederick Jelinek:
Every time I fire a linguist, the performance of the speech recognizer goes up.
Main enablers of this trend are:
- Increasing hardware capabilities
- Decreasing hardware costs
- Increasing data availability
- Algorithmic developments
↑ Increasing hardware capabilities
Capabilities of computer hardware relevant to AI, particularly that of Graphics Processing Units (GPUs), continue to increase mostly due to advancements in transistor size and number of cores. This progress is expected to continue until 2031 ± 4 years◥ [1].
This trend enables us to run AI trainings in a few days or weeks which would have taken couple of million years just a decade back. Nowadays, it is not unusual to encounter training durations of a few months but generally it is not worth to run trainings longer than 15 months◥ [2].
↓ Decreasing hardware costs
Tech is deflationary◥. The cost of genome sequencing was around $100,000,000 per human genome in 2001. This figure decreased to $100,000 around 2009 and nowadays it is less than $1000 [3]. It is crucial to understand that this trend affects almost all genomics research activities. In other words, it "trickles down"◥.
Computer hardware is no different. That's why the cheapest smartwatch today has several orders of magnitude more memory than the most expensive computer in 1969 that landed us on the moon. Historically, number of computations 1$ can afford doubled approximately every 2.5 years in the field of AI [4].
↑ Increasing data availability
Collecting, storing, and sharing data is ridiculously easy compared to 1980s (thanks Internet!). It is dirt cheap too. Even though labeling data is still costly, it gets cheaper with certain tricks◥. Furthermore, most of the state-of-the-art AI models utilize unlabeled data by self-supervision◥ anyway.
↑ Algorithmic developments
Most influential algorithmic advancements regarding AI focus heavily on trying to find methods that can scale. In other words, (a) ability to accommodate more training data (preferably unlabeled) (b) to reach higher performance (c) without needing proportionally more manual work or domain knowledge. Regarding these 3 criteria, traditional machine learning methods fall short◥ and general-purpose methods such as deep representation learning or reinforcement learning don't◥. And larger models with a lot of parameters tend to scale better due to certain theoretical reasons◥ [5, 6]. This creates an incentive for increasing the compute. Even though there are significant advancements that focus on data- and compute-efficiency of AI training such as importance sampling◥ or curriculum learning◥, they focus on the "bang for your buck" compute and have little effect on the limits of total compute in an absolute sense.
These factors mentioned above compounds, which renders the growth to be exponential⧉. Or in "tech bro" words: it scales. Based on the reasonable assumption that there is nothing Venture Capital loves more than something that scales, investments most likely further amplifies this growth. Can we quantify it then?
The goal here is to have an approximate, yet data-driven estimate of rate of AI progress.
Analysis
Two trends are analyzed:
1. Training Compute
2. Number of Model Parameters
Data consists of influential◥ AI models of last 40 years. It is curated from different sources [7-11]. I have corrected some of the calculations based on more up-to-date info and added more models either by retrieving from corresponding publications or by manual calculations. While most of the models in the data are neural networks, I am using the term "AI" somewhat loosely here.
1. Training Compute
↓ Explore the interactive chart below (1st of 2) - Desktop viewing is recommended ↓
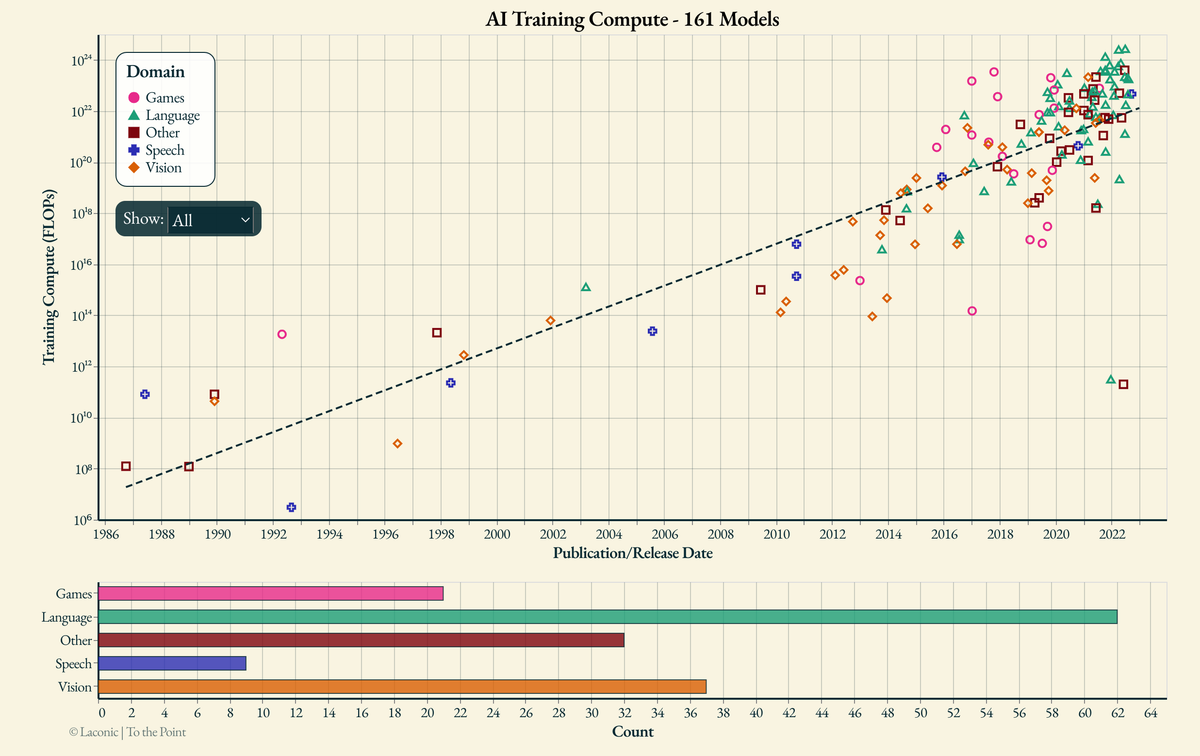
Each point (●▴■✚♦) represents an influential AI model:
Publication date vs. Total number of computations to train it
The typical metric denoting the total compute to train an AI system is Floating Point Operations (FLOPs) which is essentially the total number of additions (+) and multiplications (×). This metric always serves as a pragmatic reminder that whenever someone talks about AI, what they really mean is a computer program that adds and multiplies numbers.
Reminder: whenever someone talks about AI, what they really mean is a computer program that adds and multiplies numbers in a useful manner.
For the interested, there are 2 ways to estimate the computational resources spent to train an AI system:
Method 1: Estimate by Operation Count
This method uses number of operations in a forward pass, number of examples in the training data, and total number of training iterations [10, 11].
Pros:
- Results in estimates of higher certainty
Cons:
- Requires detailed knowledge of training and neural network architectures
Method 2 : Estimate by GPU-time
This method uses total hours of GPU usage and GPU type/model [10, 11].
Pros:
- Independent of the model architecture and training details (e.g. data augmentations)
- Lately being reported more frequently (mostly because ability to afford 1000 GPUs is a flex)
Cons:
- Requires certain level of GPU hardware knowledge
- Relies on assumptions regarding GPU utilization. Note that hardware utilization is very low (~20%) when training large models due to various reasons. As of February 2023, Google's ViT-22B is the only large model that passes 50% FLOPs utilization rate to the best of my knowledge.
2. Number of Model Parameters
We have more samples for the parameter trend analysis as it is reported relatively more frequently and there is no need to estimate anything.
↓ Explore the interactive chart below (2nd of 2) - Desktop viewing is recommended ↓
Each point (●▴■✚♦) represents an influential AI model:
Publication date vs. Number of model parameters
Is this a forecast?
Not in a strict sense.
While some previous work present similar analyses as a definitive forecast, I don't buy that. First, the moment this kind of analysis is presented as a forecast, it creates an urge to "improve" the trend fit. Then one ends up fitting higher order curves, removing outliers, dividing the timeline into arbitrary sub-timelines (e.g. before deep learning vs. after deep learning) or sub-categories (e.g. language vs. vision models) in order to "explain" the data better. That's an invitation to overfitting and calculating confidence intervals⧉ does not change that fact. Second, there is bias◥ in the data. Finally, the amount of data at hand is really not that much to reliably forecast such a complex phenomenon. That's why I present this as a descriptive analysis rather than a predictive one.
In fact, to make this point I created 4 different partitions of the same data:
- Before & After Deep Learning (DL): this is already controversial because when did DL start really? Previously, 2010 [9] as well as 2012 [12] has been suggested as the start for similar analysis. I have always considered Hinton's Deep Belief Net paper coupled with the contrastive divergence algorithm [13] in 2006 to be the start of Deep Learning era.
- Domain-specific: Treating Games, Language, Speech, and Vision as separate categories
- Before & After Commoditization of AI: I take TensorFlow⧉'s initial release date (end of 2015) as the start of the AI commoditization era. Before that, you had to write your own GPU kernel in Theano⧉ like a total loser but since then you just spend double amount of time trying to make TensorFlow work with a GPU like a cool nerd.
- With & Without Self-supervised Learning
As depicted below, all of these partitions of the same data result in rather different growth rates (mind the log-scale!):
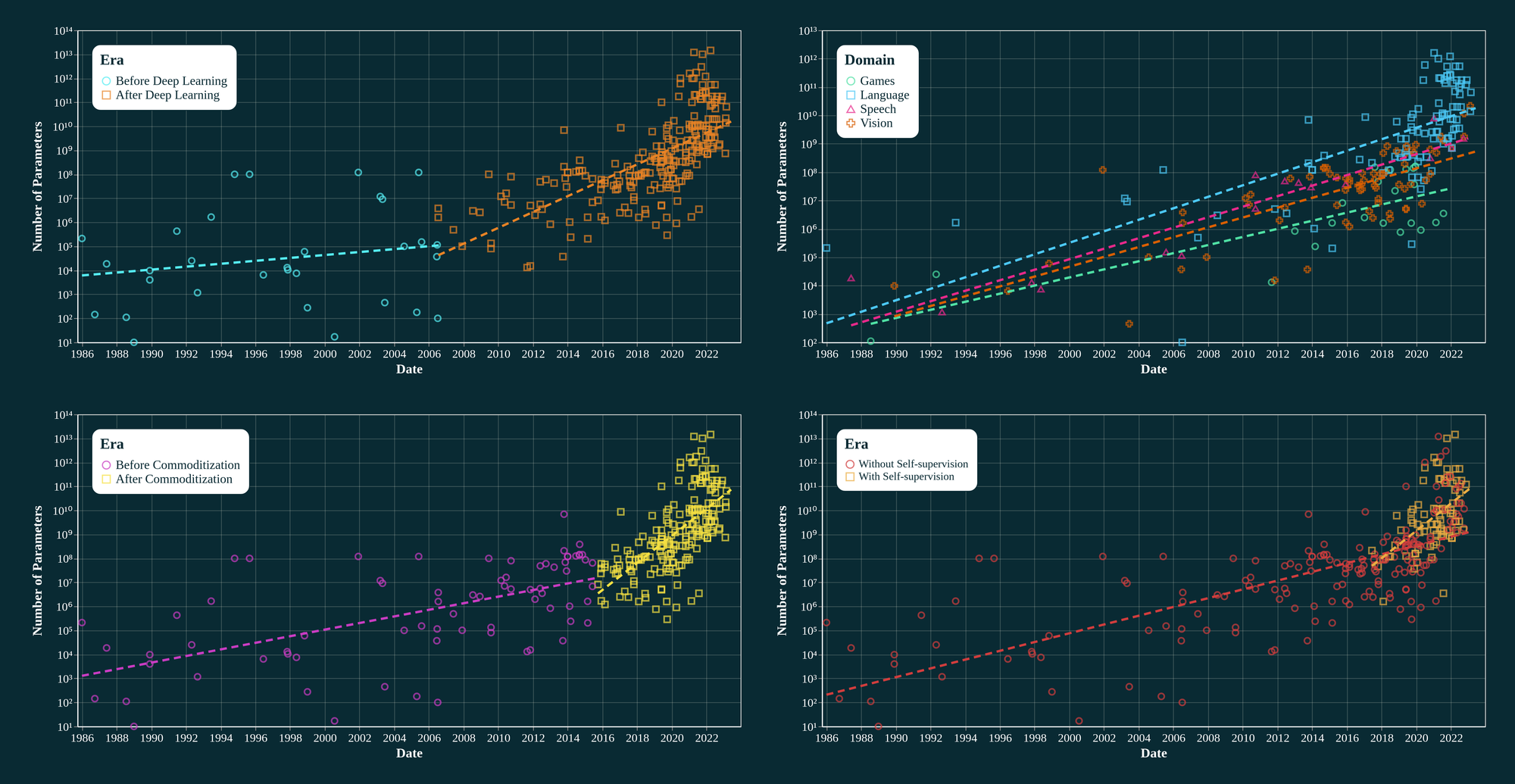
One might as well construct all sorts of argumentations for why a certain partition totally makes sense:
- Before & during 202X global chip shortage → slowdown of compute steroid supply
- Low & high interest rate eras → affects AI investments
- Generative AI era vs before
- And most importantly, before & after NVIDIA CEO, Jensen Huang⧉, got obsessed with wearing a black leather jacket → well, it improves the fit
The point is, over-focusing on a single-number growth rate sounds like "We (as individuals, companies, societies) are ready only if AI capabilities double every 12 months instead of every 9 months next decade". This does not seem to match with the reality.
Implications
Quantifying AI compute trends, even only approximately, is useful simply because it tells a lot about the overall progress of AI as a field. One might of course ask isn't it bizarre that such a low-level detail as "number of additions and multiplications" is a reasonable indicator of a high-level concept as "AI progress" in the long run? Yes, it is! Does it have to be like this, meaning that do AI leaps have to come from leveraging of AI compute? Absolutely not! Yet, has it been like this for decades? Definitely yes! It is high time we face the music.
For Individuals
- If your pursuit has aspects that can be automated, you will be able to focus more and more on what actually matters to you regarding your pursuit. But the financial gap between the top and the average will also increase more and more. Let's explain with an example. Recording "killed" the local bands. PA systems "killed" the big band. DJs "killed" the live bands. Drum machines "killed" the drummer. Synthesizers "killed" the other musicians. AI "is killing" the composers. And yet, it is the best time to be a musician in the history. You can compose, record, synthesize, mix any musical idea of yours with open source tools and share it with the world via Spotify or SoundCloud in a matter of days, if not hours. But it is the worst time to be a professional musician. Similar trends will hit other professions as well.
- Rate of progress shows that numerous professions will not be automated anytime soon. On the other hand, even if an individual has zero risk of being fully automated, it does not guarantee that their livelihood will not be affected at all. This is mostly due to basic microeconomics (supply & demand). If 25% of your peers are automated away, there will be a high supply of people willing to or at least attempting to provide the same thing as you do. In other words, competition will increase and you will have to decrease your prices, regardless of whether you can be fully automated or not.
For Companies
- Most companies have to focus on short to mid-term due to financial realities. If they are creating value by productionizing AI systems, the rate of AI progress is just right for that. It is not so high that half of the expenses has to go to AI R&D and compute to stay competitive and it is not so low that the board can ignore the whole AI adoption until they are retired.
- Developing state-of-the-art AI is very expensive (understanding, developing, training, deploying, maintaining) for most companies but the trend clearly shows that, whatever the AI approach is, it will be a commodity in a few years. One effective way to ride this wave smoothly by staying in the sweet spot is to combine domain expertise with AI to create competitive advantage. Industry knows that some computer science grad student will find a smart way to scale the AI computation and the domain expertise will be obsolete at some point but that is not happening this quarter.
For Policymakers
- Immense pressure, lobbying, and fear-mongering should be expected from the GPU-rich big dogs (OpenAI, Anthropic etc.) because regulatory capture⧉ is a solid strategy.
- The exponential (as opposed to linear) progress of AI is particularly bad news for policymaking because creation of high-level policies takes time and our policymaking efficiency is probably not increasing exponentially. I couldn't come up with any silver lining⧉ for policymaking during AI adoption. It will be a dumpster fire!
The Point
AI compute is an appropriate proxy for AI progress and it doubles every 9 months. Overall trend is useful to know and is expected to continue, yet forecasting it is not an exact science.
References
[1] Hobbhahn et al., "Predicting GPU Performance", 2022
[2] Sevilla et al., "The Longest Training Run", 2022
[3] NIH National Human Genome Research Institute, "The Cost of Sequencing a Human Genome", 2021
[4] Hobbhahn et al., "Trends in GPU Price-performance", 2022
[5] Choromanska et al., "The Loss Surfaces of Multilayer Networks", 2015
[6] Sagun et al., "Explorations on High Dimensional Landscapes", 2014
[7] Thompson et al. "The Computational Limits of Deep Learning", 2020
[8] Lohn et al., "How Much Longer Can Computing Power Drive Artificial Intelligence Progress?", 2021
[9] Sevilla et al., "Compute Trends Across Three Eras of Machine Learning", 2022
[10] Amodei et al., "AI and Compute", 2018
[11] Brown et al., "Language Models Are Few-shot Learners", 2020
[12] Alom et al. "The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches", 2018
[13] Hinton et al., "A Fast Learning Algorithm for Deep Belief Nets", 2006
Cite This Article
Gencoglu, Oguzhan. "4 Decades of AI Compute." Laconic, 7 Feb. 2023, www.laconic.fi/ai-compute/.
Author: Oguzhan Gencoglu
Published: 7 February 2023 | Updated: 27 February 2023